



ArXiv, 2017
A Survey of Available Corpora for Building Data-Driven Dialogue Systems
Call for contributions! We're always looking for more datasets. Feel free to send us a pull request!
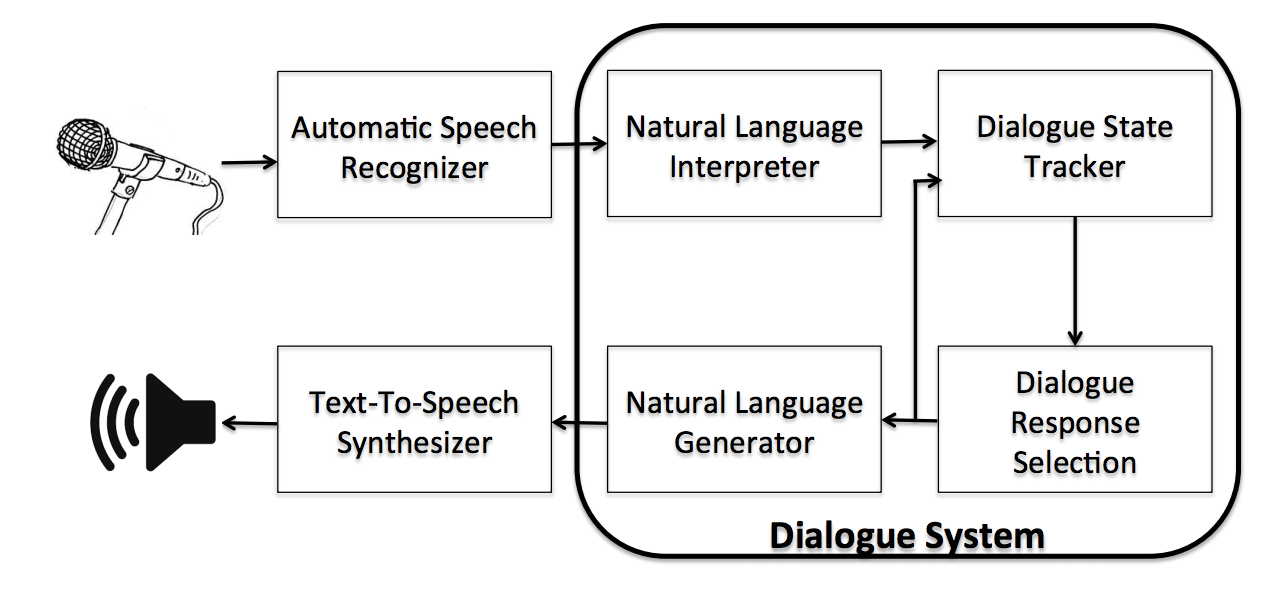
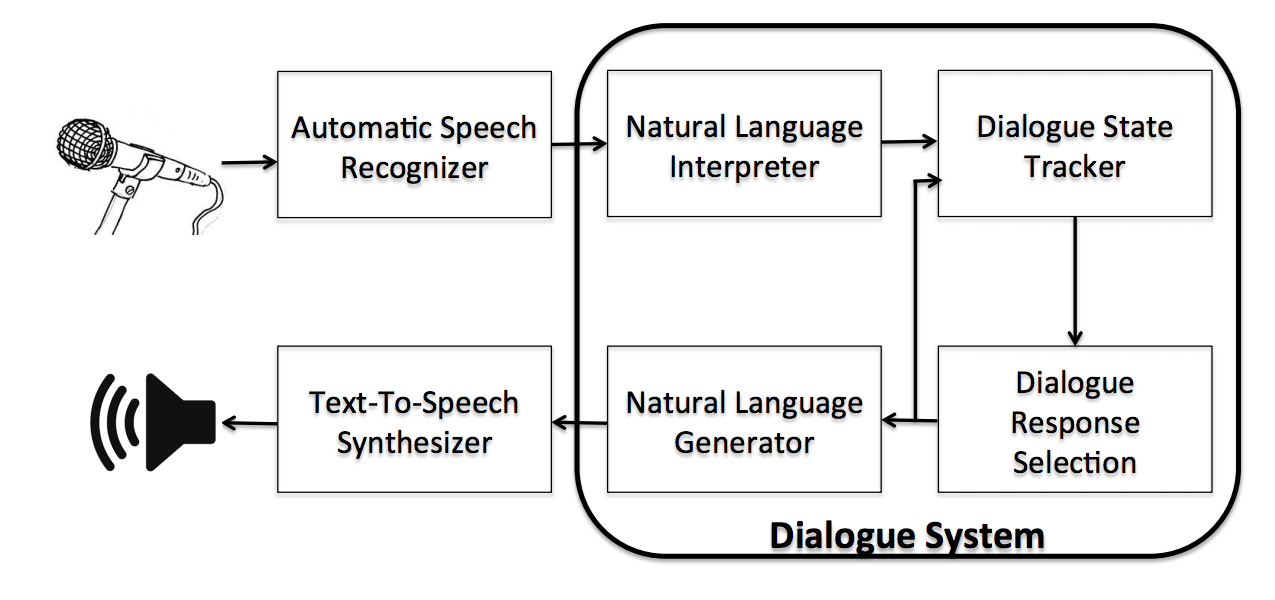
A basic outline of a dialog system.
Abstract
During the past decade, several areas of speech and language understanding have witnessed substantial breakthroughs from the use of data-driven models. In the area of dialogue systems, the trend is less obvious, and most practical systems are still built through significant engineering and expert knowledge. Nevertheless, several recent results suggest that data-driven approaches are feasible and quite promising. To facilitate research in this area, we have carried out a wide survey of publicly available datasets suitable for data-driven learning of dialogue systems. We discuss important characteristics of these datasets, how they can be used to learn diverse dialogue strategies, and their other potential uses. We also examine methods for transfer learning between datasets and the use of external knowledge. Finally, we discuss appropriate choice of evaluation metrics for the learning objective.
Materials
Acknowledgements
The authors gratefully acknowledge financial support by the Samsung Advanced Institute of Technology (SAIT), the Natural Sciences and Engineering Research Council of Canada (NSERC), the Canada Research Chairs, the Canadian Institute for Advanced Research (CIFAR) and Compute Canada. Early versions of the manuscript benefited greatly from the proofreading of Melanie Lyman-Abramovitch, and later versions were extensively revised by Genevieve Fried and Nicolas Angelard-Gontier. The authors also thank Nissan Pow, Michael Noseworthy, Chia-Wei Liu, Gabriel Forgues, Alessandro Sordoni, Yoshua Bengio and Aaron Courville for helpful discussions.
Citation
Dataset Statistics
Human-Machine Dialogue Datasets
| Name | Type | Topics | Avg. # of turns | Total # of dialogues | Total # of words | Description | Links |
|
Let's Go! [Raux et al., 2005] |
Spoken | Bus schedules | -- | 171,128 | -- | Bus ride information system | Info and download |
|
DSTC1 [Williams et al., 2013] |
Spoken | Bus schedules | 13.56 | 15,000 | 3.7M | Bus ride information system | Info and download |
|
DSTC2 [Henderson et al., 2014b] |
Spoken | Restaurants | 7.88 | 3,000 | 432K | Restaurant booking system | Info and Download |
|
DSTC3 [Henderson et al., 2014a] |
Spoken | Tourist information | 8.27 | 2,265 | 403K | Information for tourists | Info and Download |
| CMU Communicator Corpus [Bennett and Rudnicky, 2002] |
Spoken | Travel | 11.67 | 15,481 | 2M* | Travel planning and booking system | Info and Download |
| ATIS Pilot Corpus [Hemphill et al., 1990] |
Spoken | Travel | 25.4 | 41 | 11.4K* | Travel planning and booking system | Info Download |
| Ritel Corpus [Rosset and Petel, 2006] |
Spoken | Unrestricted/ Diverse Topics | 9.3* | 582 | 60k | An annotated open-domain question answering spoken dialogue system | Info Contact corpus authors for download |
| DIALOG Mathematical Proofs [Wolska et al., 2004] | Spoken | Mathematics | 12 | 66 | 8.7K* | Humans interact with computer system to do mathematical theorem proving | Info Contact corpus authors for download |
| MATCH Corpus [Georgila et al., 2010] |
Spoken | Appointment Scheduling | 14.0 | 447 | 69K* | A system for scheduling appointments. | Info and download |
| Maluuba Frames [El Asri et al., 2017] |
Chat, QA & Recommendation | Travel & Vacation Booking | 15 | 1369 | - | For goal-driven dialogue systems. Semantic frames labeled and actions taken on a knowledge-base annotated. | Info and Download |
| Key-Value Retrieval dataset [Eric and Manning, 2017] |
Chat, QA | Calendar, Weather, POI navigation | 5.25 | 3031 | - | For Task-oriented dialogue systems. Intent, slots and KB annotated for each session. | Info and Download |
| MultiWOZ [Budzianowski et al. 2018] |
Chat, QA, Recommendations | Travel | 14 | 10438 | - | For goal-driven dialogue systems. Fully labelled on both user and system sides. | Info and Download |
Table 1: Human-machine dialogue datasets. Starred (*) numbers are approximated based on the average number of words per utterance.
Human-Human Constrained Dialogue Datasets
| Name | Topics | Total # of dialogues | Total # of words | Total length | Description | Links |
| HCRC Map Task Corpus [Anderson et al., 1991] | Map-Reproducing Task | 128 | 147k | 18hrs | Dialogues from HLAP Task in which speakers must collaborate verbally to reproduce on one participant’s map a route printed on the other’s. | Info and Download |
| The Walking Around Corpus [Brennan et al., 2013] | Location Finding Task | 36 | 300k* | 33hrs | People collaborating over telephone to find certain locations. | Info and Download |
| Green Persuasive Database [Douglas-Cowie et al., 2007] | Lifestyle | 8 | 35k* | 4hrs | A persuader with (genuinely) strong pro-green feelings tries to convince persuadees to consider adopting more ‘green’ lifestyles. | Info Download |
| Intelligence Squared Debates [Zhang et al., 2016] | Debates | 108 | 1.8M | 200hrs* | Various topics in Oxford-style debates, each constrained to one subject. Audience opinions provided pre- and post-debates. | Info and Download |
| The Corpus of Professional Spoken American English [Barlow, 2000] | Politics, Education | 200 | 2M | 220hrs* | Interactions from faculty meetings and White House press conferences. | Info and Download (Download may require purchase.) |
| MAHNOB Mimicry Database [Sun et al., 2011] | Politics, Games | 54 | 100k* | 11hrs | Two experiments: a discussion on a political topic, and a role-playing game. | Info and Download |
| The IDIAP Wolf Corpus [Hung and Chittaranjan, 2010] | Role-Playing Game | 15 | 60k* | 7hrs | A recording of Werewolf role-playing game with annotations related to game progress. | Info and Download |
| SEMAINE corpus [McKeown et al., 2010] | Emotional Conversations | 100 | 450k* | 50hrs | Users were recorded while holding conversations with an operator who adopts roles designed to evoke emotional reactions. | Info and Download |
| DSTC4/DSTC5 Corpora [Kim et al., 2015,Kim et al., 2016] | Tourist | 35 | 273k | 21hrs | Tourist information exchange over Skype. | DSTC4 DSTC5 (DSTC4 Training Set with Chinese lang. Test Set) |
| Loqui Dialogue Corpus [Passonneau and Sachar, 2014] | Library Inquiries | 82 | 21K | 140* | Telephone interactions between librarians and patrons. Annotated dialogue acts, discussion topics, frames (discourse units), question-answer pairs. | Info and Download |
| MRDA Corpus [Shriberg et al., 2004] | ICSI Meetings | 75 | 11K* | 72hrs | Recordings of ICSI meetings. Topics include: ICSI meeting recorder project itself, automatic speech recognition, natural language processing and neural theories of language. Dialogue acts, question-answer pairs, and hot spots. | Info and Download |
| TRAINS 93 Dialogues Corpus [Heeman and Allen, 1995] | Railroad Freight Route Planning | 98 | 55K | 6.5hrs | Collaborative planning of railroad freight routes. | Info and Download |
| Verbmobil Corpus [Burger et al., 2000] | Appointment Scheduling | 726 | 270K | 38Hrs | Spontaneous speech data collected for the Verbmobil project. Full corpus is in English, German, and Japanese. We only show English statistics. | Info Download I Download II |
| ICT Rapport Datasets [Gratch et al., 2007] | Sexual Harassment Awareness | 165 | N/A | N/A | A speaker tells a story to a listener. The listener is asked to not speak during the story telling. Contains audio-visual data, transcriptions, and annotations. | Info and Download |
Table 2: Human-human constrained spoken dialogue datasets. Starred (*) numbers are estimates based on the average rate of English speech from the National Center for Voice and Speech.
Human-Human Spontaneous Dialogue Datasets
| Name | Topics | Total # of dialogues | Total # of words | Total length | Description | Links |
| Switchboard [Godfrey et al., 1992] | Casual Topics | 2,400 | 3M | 300hrs* | Telephone conversations on pre-specified topics | Info and Download |
| British National Corpus (BNC) [Leech, 1992] | Casual Topics | 854 | 10M | 1,000hrs* | British dialogues many contexts, from formal business or government meetings to radio shows and phone-ins. | Info and Download |
| CALLHOME American English Speech [Canavan et al., 1997] | Casual Topics | 120 | 540k* | 60hrs | Telephone conversations between family members or close friends. | Info and Download |
| CALLFRIEND American English Non-Southern Dialect [Canavan and Zipperlen, 1996] | Casual Topics | 60 | 180k* | 20hrs | Telephone conversations between Americans with a Non-Southern accent. | Info and Download |
| The Bergen Corpus of London Teenage Language [Haslerud and Stenström, 1995] | Unrestricted | 100 | 500k | 55hrs | Spontaneous teenage talk recorded in 1993. Conversations were recorded secretly. | Info and Download |
| The Cambridge and Nottingham Corpus of Discourse in English [McCarthy, 1998] | Casual Topics | - | 5M | 550hrs* | British dialogues from wide variety of informal contexts, such as hair salons, restaurants, etc. | Info and Download Note: CANCODE is a subset of the Cambridge English Corpus. |
| D64 Multimodal Conversation Corpus [Oertel et al., 2013] | Unrestricted | 2 | 70k* | 8hrs | Several hours of natural interaction between a group of people | Contact corpus authors for data. |
| AMI Meeting Corpus [Renals et al., 2007] | Meetings | 175 | 900k* | 100hrs | Face-to-face meeting recordings. | Info and Download |
| Cardiff Conversation Database (CCDb) [Aubrey et al., 2013] | Unrestricted | 30 | 20k* | 150min | Audio-visual database with unscripted natural conversations, including visual annotations. | Info and Download |
| 4D Cardiff Conversation Database (4D CCDb) [Vandeventer et al., 2015] | Unrestricted | 17 | 2.5k* | 17min | A version of the CCDb with 3D video | Info and Download |
| The Diachronic Corpus of Present-Day Spoken English [Aarts and Wallis, 2006] | Casual Topics | 280 | 800k | 80hrs* | Selection of face-to-face, telephone, and public discussion dialogue from Britain. | Info and Download |
| The Spoken Corpus of the Survey of English Dialects [Beare and Scott, 1999] | Casual Topics | 314 | 800k | 60hrs | Dialogue of people aged 60 or above talking about their memories, families, work and the folklore of the countryside from a century ago. | Info Contact corpus authors for download. |
| The Child Language Data Exchange System [MacWhinney and Snow, 1985] | Unrestricted | 11K | 10M | 1,000hrs* | International database organized for the study of first and second language acquisition. | Info and Download |
| The Charlotte Narrative and Conversation Collection (CNCC) [Reppen and Ide, 2004] | Casual Topics | 95 | 20K | 2hrs* | Narratives, conversations and interviews representative of the residents of Mecklenburg County, North Carolina. | Info and Download |
| The Group Affect and Performance (GAP) Corpus [Braley and Murray, 2018] | Survival | 28 | 70K | 4hrs+ | A winter survival task | Info and Download |
| The MULTISIMO Corpus [Koutsombogera and Vogel, 2018] | Game | 18 | 26K | 3hrs+ | Family Feud-like game | Info and Download |
Table 3: Human-human spontaneous spoken dialogue datasets. Starred (*) numbers are estimates based on the average rate of English speech from the National Center for Voice and Speech.
Human-Human Scripted Dialogue Datasets
| Name | Topics | Total # of utterances | Total # of dialogues | Total # of works | Total # of words | Description | Links |
| Movie-DiC [Banchs, 2012] | Movie dialogues | 764k | 132K | 753 | 6M | Movie scripts of American films. | Contact corpus authors for data. |
| Movie-Triples [Serban et al., 2016] | Movie dialogues | 736k | 245K | 614 | 13M | Triples of utterances which are filtered to come from X-Y-X triples. | Contact corpus authors for data. |
| Film Scripts Online Series | Movie scripts | 1M* | 263K | 1,500 | 16M* | Two subsets of scripts (1000 American films and 500 mixed British/American films). | Info and Download |
| Cornell Movie-Dialogue Corpus [Danescu-Niculescu-Mizil and Lee, 2011] | Movie dialogues | 305K | 220K | 617 | 9M* | Short conversations from film scripts, annotated with character metadata. | Info and Download |
| Filtered Movie Script Corpus [Nio et al., 2014] | Movie dialogues | 173k | 86K | 1,786 | 2M* | Triples of utterances which are filtered to come from X-Y-X triples. | Info and Download |
| American Soap Opera Corpus [Davies, 2012b] | TV show scripts | 10M* | 1.2M | 22,000 | 100M | Transcripts of American soap operas. | Info and Download |
| TVD Corpus [Roy et al., 2014] | TV show scripts | 60k* | 10K | 191 | 600k* | TV scripts from a comedy (Big Bang Theory) and drama (Game of Thrones) show. | Info and Download |
| Character Style from Film Corpus [Walker et al., 2012a] | Movie scripts | 664k | 151K | 862 | 9.6M | Scripts from IMSDb, annotated for linguistic structures and character archetypes. | Contact corpus authors for data. |
| SubTle Corpus [Ameixa and Coheur, 2013] | Movie subtitles | 6.7M | 3.35M | 6,184 | 20M | Aligned interaction-response pairs from movie subtitles. | Contact corpus authors for data. |
| OpenSubtitles [Tiedemann, 2012] | Movie subtitles | 140M* | 36M | 207,907 | 1B | Movie subtitles which are not speaker-aligned. | Info and Download |
| CED (1560-1760) Corpus [Kytö and Walker, 2006] | Written Works & Trial Proceedings | - | - | 177 | 1.2M | Various scripted fictional works from (1560-1760) as well as court trial proceedings. | Info and Download |
Table 4: Human-human scripted dialogue datasets. Quantities denoted with () indicate estimates based on average dialogues per movie seen in [Banchs, 2012] and the number of scripts or works. Dialogues may not be explicitly separated in these datasets. TV show datasets were adjusted based on the ratio of average film runtime (112 minutes) to average TV show runtime (36 minutes). This data was scraped from the IMBD database (http://www.imdb.com/interfaces). ( Starred (*) quantities are estimated based on the average number of words and utterances per film, and the average lengths of films and TV shows. Estimates derived from the Tameri Guide for Writers (http://www.tameri.com/format/wordcounts.html).
Human-Human Written Dialogue Datasets
| Name | Type | Topics | Avg. # of turns | Total # of dialogues | Total # of words | Description | Links |
| NPS Chat Corpus [Forsyth and Martell, 2007] | Chat | Unrestricted | 704 | 15 | 100M | Posts from age-specific online chat rooms. | Info and Download |
| Twitter Corpus [Ritter et al., 2010] | Microblog | Unrestricted | 2 | 1.3M | 125M | Tweets and replies extracted from Twitter | Contact corpus authors for data. |
| Twitter Triple Corpus [Sordoni et al., 2015] | Microblog | Unrestricted | 3 | 4,232 | 65K | A-B-A triples extracted from Twitter | Info and Download |
| UseNet Corpus [Shaoul and Westbury, 2009] | Microblog | Unrestricted | 687 | 47860 | 7B | UseNet forum postings | Info and Download |
| NUS SMS Corpus [Chen and Kan, 2013] | SMS messages | Unrestricted | 18 | 3K | 580,668*[¯] | SMS messages collected between two users, with timing analysis. | Info and Download |
| Reddit Domestic Abuse Corpus [Schrading et al., 2015] | Forum | Abuse help | 17.53 | 21,133 | 19M-103M \triangle | Reddit posts from either domestic abuse subreddits, or general chat. | Info and Download |
| Reddit All Comments Corpus | Forum | General | -- | -- | -- | 1.7 Billion Reddit comments. | Info and Download |
| Settlers of Catan [Afantenos et al., 2012] | Chat | Game terms | 95 | 21 | - | Conversations between players in the game `Settlers of Catan'. | Info Contact corpus authors for download. |
| Cards Corpus [Djalali et al., 2012] | Chat | Game terms | 38.1 | 1,266 | 282K | Conversations between players playing `Cards world'. | Info and Download |
| Agreement in Wikipedia Talk Pages [Andreas et al., 2012] | Forum | Unrestricted | 2 | 822 | 110K | LiveJournal and Wikipedia Discussions forum threads. Agreement type and level annotated. | Info and Download |
| Agreement by Create Debaters [Rosenthal and McKeown, 2015] | Forum | Unrestricted | 2 | 10K | 1.4M | Create Debate forum conversations. Annotated what type of agreement (e.g. paraphrase) or disagreement. | Info and Download |
| Internet Argument Corpus [Walker et al., 2012b] | Forum | Politics | 35.45 | 11K | 73M | Debates about specific political or moral positions. A separate corpus (Argumentative Summary Corpus, [Walker et al., 2012b]) annotates a subset of this corpus with summaries of the arguments. | Info and Download Argument Summary Corpus |
| MPC Corpus [Shaikh et al., 2010] | Chat | Social tasks | 520 | 14 | 58K | Conversations about general, political, and interview topics. | Info and Download |
| Ubuntu Dialogue Corpus [Lowe et al., 2015a] | Chat | Ubuntu Operating System | 7.71 | 930K | 100M | Dialogues extracted from Ubuntu chat stream on IRC. | Info and Download |
| Ubuntu Chat Corpus [Uthus and Aha, 2013] | Chat | Ubuntu Operating System | 3381.6 | 10665 | 2B*[¯] | Chat stream scraped from IRC logs (no dialogues extracted). | Info and Download |
| Movie Dialog Dataset [Dodge et al., 2015] | Chat, QA & Recommendation | Movies | 3.3 | 3.1M\blacktriangledown | 185M | For goal-driven dialogue systems. Includes movie metadata as knowledge triples. | Info and Download |
| DailyDialog Dataset [Li et al., 2017] | Chat | Daily Life | 7.9 | 13K | 1.5M | Conversations extracted from English language educational texts. Labeled with emotions. | Info and Download |
Table 5: Human-human written dialogue datasets. Starred (*) quantities are computed using word counts based on spaces (i.e. a word must be a sequence of characters preceded and followed by a space), but for certain corpora, such as IRC and SMS corpora, proper English words are sometimes concatenated together due to slang usage. Triangle (\triangle) indicates lower and upper bounds computed using average words per utterance estimated on a similar Reddit corpus Schrading [2015]. Square ([¯]) indicates estimates based only on English part of the corpus. Note that 2.1M dialogues from the Movie Dialog dataset (\blacktriangledown) are in the form of simulated QA pairs. Dialogs indicated by () are contiguous blocks of recorded conversation in a multi-participant chat. In the case of UseNet, we note the total number of newsgroups and find the average turns as average number of posts collected per newsgroup. () indicates an estimate based on a Twitter dataset of similar size and refers to tokens as well as words.