Fully Convolutional Seq2Seq for Character-Level Dialogue Generation

Turing test and beyond...
Different approaches for creating conversational systems
Massive amounts of noisy dialogue data
Recurrent Models and Improvements
In Machine Translation and Dialogue Systems
Fully Convolutional
Character-Level Conversational System
Why is this worth pursuing?
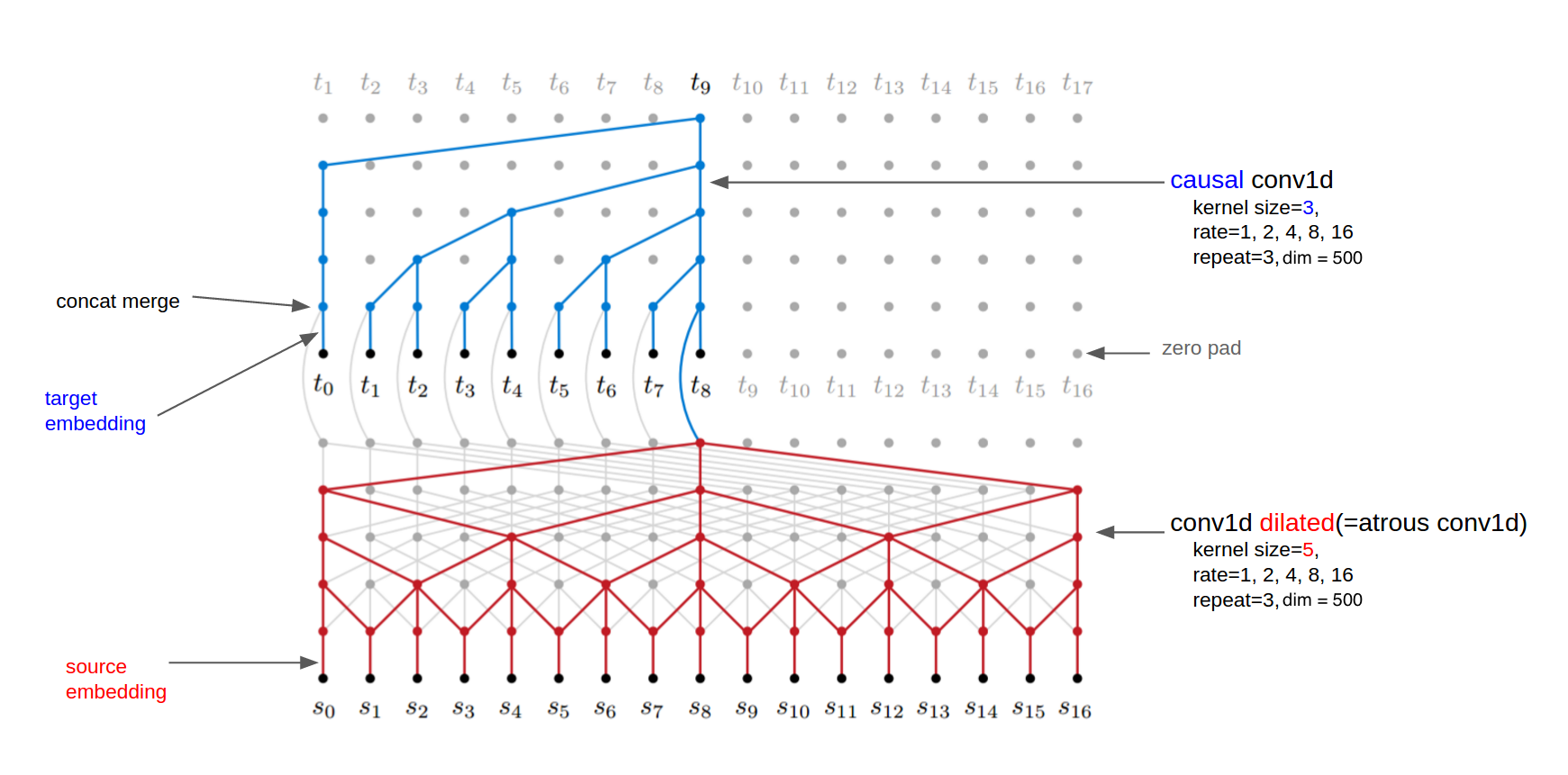
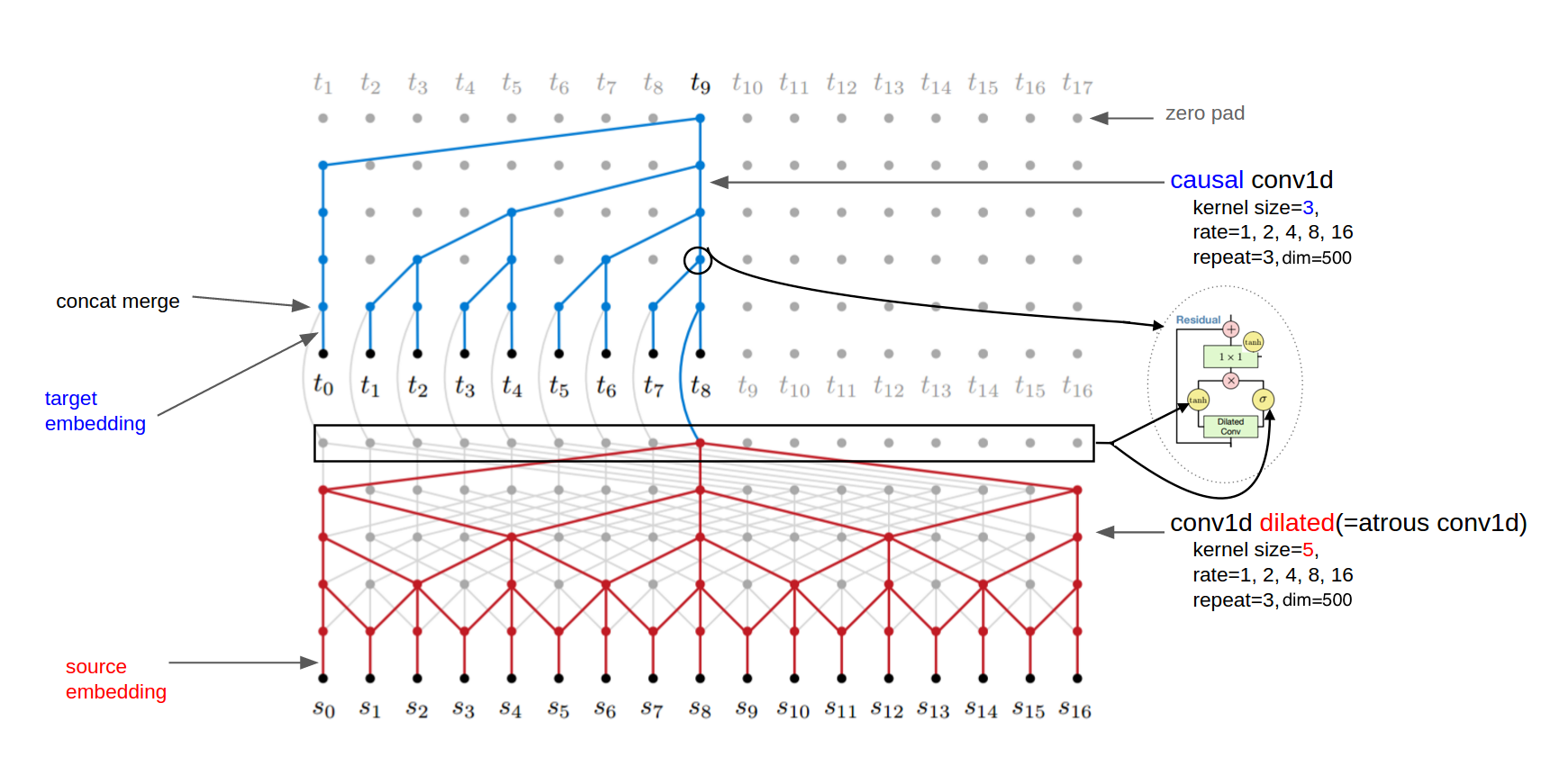
Dilated and Causal Convolutions

Modified ByteNet Architecture
Modified ByteNet Architecture
Global Conditioning
Objective Function
Softmax Categorical Cross Entropy
Word-Level Seq2Seq Baseline With Attention
Used repositories and technologies
Results (Questionaire Scores)
Results (Questionaire Scores)
Results (Questionaire Scores)
Results (Sample Responses Seq2Seq)
Results (Baseline ByteNet)
Results (Modified ByteNet)
Results (Sample Responses Human)
Future Work (beyond project)
Questions
(Did you like the web presentation?)
(Want to know anything about the algorithms or data?)
use arrow keys
to navigate




 Used Harvard Torch Implementation default parameters (500 hidden units, 2 layers).
Used Harvard Torch Implementation default parameters (500 hidden units, 2 layers).