
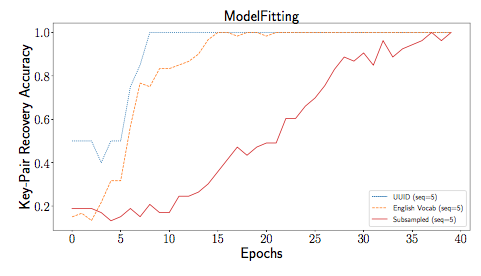
AAAI/ACM conference on Ethics and Safety (in submission), 2017
Detailed statistics for bias detection (including min/max bias scale samples, etc.) can be found here:
1000 sampled evaluations of the bias model for all datasets can be found:
Similarly, for HRED and VHRED bias statistics can be found here:
[ Twitter VHRED Beam ]
[ Twitter VHRED Stochastic ]
[ Twitter HRED Beam ]
[ Twitter HRED Stochastic ]
[ Twitter VHRED Stochastic ]
[ Twitter HRED Beam ]
[ Twitter HRED Stochastic ]
And HRED and VHRED 1000 sampled evaluations can be found here: